用 DSPy 框架构建可自动优化的 AI 系统(上)
· 00
DSPy 是什么
DSPy(Declarative Self-Improving Python)是一个构建模块化 AI 系统的声明式框架。
- 给定任务和少量训练数据,框架能自动优化提示词和模型权重,指导模型高质量输出。
- 适合 RAG、Agent、复杂多步任务。
核心理念:通过可组合、可测试、可优化的 Python 模块,用算法优化和调整 LM 提示和权重,最小化人工 prompt。
| 核心概念 | 作用 | 关键问题 | 例子 |
|---|---|---|---|
| Signature | 定义 LLM 的输入/输出规范(schema) | • 给模型输入什么 • 期望模型输出什么 | • 输入:用户 query 和任务、GUI 知识 • 输出:高成功率低用户成本的自动打车操作流 |
| Module | 通过自定义逻辑与 LLLM 交互的接口。对 Signature 应用推理策略。 | • 程序由哪些模块组成 • 这些模块负责干什么 | 任务理解,状态检查,解空间构建,不确定性评估,澄清,安全确认 |
| Optimizer | 根据标注数据,自动编译成 Few-Shot 示例、Prompt 模板,或微调 LoRA/FT 参数 | • 评估标准是什么,用哪些数据 • 模型用什么方法优化 | • 评估标准:任务完成率,交互成本 • 数据:成功打车的 trace • 方法:MIPROv2 |
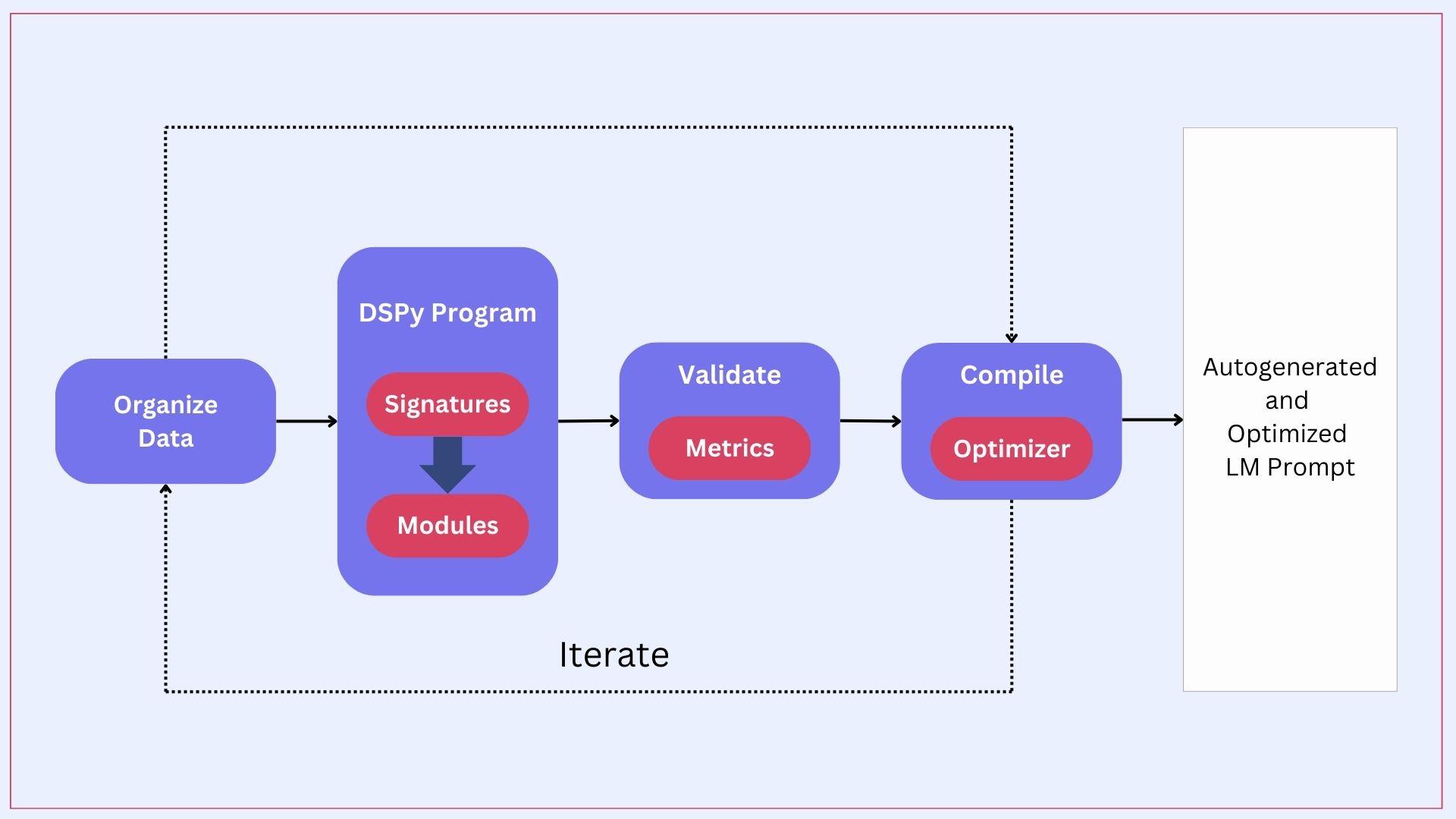
DSPy 用 Signature + Module 把任务拆成可组合步骤,然后用 Optimizer 编译整条流水线,自动生成高质量指令/示例/权重。
类比:DSPy 可以替代厨师,自动迭代出最佳菜品
- 点菜单 — Signature
- 厨房工序 — Module
- 机器人主厨 — Optimizer
| DSPy 元件 | 厨房角色 | 细节 & 过程 | 优势 |
|---|---|---|---|
| Signature | 点菜单 | - 顾客需求:主料=海鲜,意面 酱=番茄 口味=鲜甜- 只声明“要什么”,不写做法。 | 声明式:只关心输入/输出,屏蔽实现细节。 |
| Module | 厨房工序:炉台 & 配菜区 | if 海鲜不足: 退到冷柜补货先焯虾仁,再煸蒜末 → 倒番茄酱 → 收汁 业务规则(焯水 → 煸香 → 收汁)写入程序; “什么口味用户喜欢”交给 LLM 生成和试验。 | 逻辑/语言解耦:可单元测试,不怕 LLM 升级。 |
| Optimizer | AI 总厨反复试味 | 1. 搜示例:把 20 份历史好评菜谱组合成不同 few-shot 套餐; 2.尝味评分:每次做完请品控员打分(准确率、成本、咸淡); 3.进化搜索:把高分菜谱微调——加罗勒?换意面粗细? 4.LoRA 微调:相当于给 AI 总厨加“秘密调味包”,在 100 份评价数据上再训练味觉偏好。 | 自动优化:示例、提示、超参、权重一站式搜索;不用人肉调味。 |
| compile() 产物 | 最终菜品 | - 保存:最优 prompt +示例,温度/检索 k,LoRA 权重…… - 点菜时直接调用,出菜稳定可复现。 | 可版本化 & 热插拔:JSON+LoRA 文件随时上新或回滚。 |
用流程图表示就是:

示例:简单 QA 系统
import dspy
# 1. 配置语言模型
dspy.settings.configure(lm=dspy.OpenAI(model="gpt-3.5-turbo"))
# 2. 定义任务签名
class BasicQA(dspy.Signature):
"""基于给定上下文回答问题。"""
context: str = dspy.InputField(desc="与问题相关的段落")
question: str = dspy.InputField(desc="用户的问题")
answer: str = dspy.OutputField(desc="问题的答案")
# 3. 创建具有思维链推理的模块
qa = dspy.ChainOfThought(BasicQA)
# 4. 使用它
context = "巴黎是法国的首都。"
question = "法国的首都是什么?"
result = qa(context=context, question=question)
print(result.answer) # 输出:巴黎如何用 DSPy 构建可自动调优的 AI 系统:从声明到编译
- 定义任务:用 Signature 描述任务;用 Module 实现“先检索再生成”等逻辑。
- 定义指标:如 accuracy、BLEU、自定义 cost。
- 选择优化器:BootstrapFewShot、COPRO、K-NN Few-Shot 等。
compile():DSPy 自动搜索示例 / 生成 synthetic data / 微调,小到 prompt 大到权重。- 评估/迭代:当模型或数据变了,再次编译即可。
dspy.Evaluate支持 A/B 对比与持续学习。
典型场景与示例
- RAG 管道:官方教程展示了 Tech QA 任务,在同一段代码里组合 Retriever + Generator,并用优化器同时调检索和生成提示,显著提升 F1。
- 多步 Agent / 工具调用:DSPy 模块可嵌套循环,配合 self-consistency 或外部工具形成反思-执行代理,对推理链进行一致性投票减少幻觉。
- ReAct 代理:把工具列表(如“读屏/点按/输入/抓取订单状态”等)交给
dspy.ReAct,让模型在“思考 → 行动 → 观察”的循环中选择工具;再用 MIPROv2 或 BootstrapFewShot 端到端优化。
- ReAct 代理:把工具列表(如“读屏/点按/输入/抓取订单状态”等)交给
极简打车助手 Agent
import dspy
# 1) 选择模型(可换)
dspy.configure(lm=dspy.LM("openai/gpt-4o-mini"))
# 2) 定义任务(签名与模块)
class JudgeStep(dspy.Signature):
"""判断一个代理步骤是否合理,并提出改进建议"""
context: str
action: str
verdict: bool
critique: str
judge = dspy.ChainOfThought(JudgeStep)
# 3) 组装成程序
class AgentStep(dspy.Module):
def forward(self, context):
# 这里可以先 Predict 再 ReAct,这里为演示省略
return judge(context=context, action="tap('打车')")
program = AgentStep()
# 4) 定义指标(玩具版:只要 verdict=True 算 1 分)
def metric(example, pred) -> float:
return 1.0 if getattr(pred, "verdict", False) else 0.0
# 5) 少量训练/验证样例(真实项目用你的回放数据)
trainset = [dspy.Example(context="已定位到公司门口, 需要叫车").with_inputs("context")]
# 6) 选择优化器并编译
from dspy.teleprompt import MIPROv2
opt = MIPROv2(metric=metric)
compiled = opt.compile(program, trainset=trainset) # 返回“已优化程序”
# 7) 推理
pred = compiled("已定位到公司门口, 需要叫车")
print(pred.verdict, pred.critique)DSPy 的优势
在平时的 PE 优化中,你可以也会遇到这些痛点:
| 维度 | 传统 Prompt 优化 | 使用 DSPy 后的做法 |
|---|---|---|
| 核心思路 | 人工修改长 prompt,靠经验调顺序、示例 | 声明式 Signature + 模块化代码 + Optimizer 自动搜索最优方案 |
| 提示模板改写 | 人工重写,多轮 AB 测试 | COPRO / GEPA 演化提示,遗传 + 自反思 |
| 业务逻辑 | 混在一段大 prompt 里,难以单测 | 业务逻辑写在 Python Module;LLM 仅补语言 |
| 参数调优 | 通过实验脚本手动网格搜索 | Optimizer 将超参视为可学参数一并搜索 |
| 在线反馈利用 | 另写 ETL → 手动改 prompt | 日志 → trainset_increment → 夜间 compile() 自动增量学习 |
| 安全/风险控制 | 人工列规则,手工检查 prompt | 规则写在 Module;risk_penalty 纳入 metric |
| 可观测性 | 需自建日志系统;难还原完整 prompt | inspect_history() 一键查看历史消息 |
| 协作成本 | Design ↔︎ Dev ↔︎ Ops 多角色协调 | DSL (Signature/Module) 代码即文档 |
| 维护难度 | 模型升级 → 全部 prompt 回归 | 大部分规则在 Python,提示自动再编译 |
| 长期性能 | 靠人工定期复盘,效果波动 | 每日自动编译,自监督渐进提升 |
| 投入估算 | 早期人力小;数据增多后维护爆炸 | 初期写代码&指标;后期维护自动化 |
通过提供结构化模块、自动优化和组合模式,DSPy 使开发者能够构建:
- 更可靠:结构化代码比字符串提示更不易出错
- 更可移植:易于更换模型并适应新需求
- 更可优化:通过编译和优化自动改进
- 更可维护:清晰、模块化的结构易于理解和修改
DSPy vs LangChain
| 评估维度 | LangChain | DSPy | 说明 |
|---|---|---|---|
| 上手速度 | 9 | 6 | LangChain 文档 + 示例丰富 |
| 生态丰富度 | 9 | 5 | DSPy 更聚焦内核 |
| 自动优化能力 | 4 | 9 | DSPy 核心竞争力 |
| 可编译/可重构性 | 6 | 9 | Signature → Program |
| 工具/Agent 生产案例 | 9 | 5 | LangChain 成熟 |
| 推理质量迭代潜力 | 6 | 9 | DSPy 算法化 |
| 学术/研究友好 | 6 | 9 | 声明式 + 可控实验 |
| 成本精细化管理 | 7 | 7 | 均需自建策略 |
| 易与现有后端集成 | 8 | 7 | LangChain 适配器多 |
| 长期可维护性(结构清晰) | 7 | 8 | DSPy 结构化语义更清晰 |
(分值仅用于相对直觉,不是客观指标)
- LangChain:像一个“拼装厂” + “适配层”——让各种资源(模型、向量库、工具、Agent、工作流)快速跑通。
- DSPy:像一个“编译器 + 优化器”——把 LLM 互动抽象为可声明、可训练、可演化的程序。
- 选型核心分界:是在“解决集成问题”还是“解决质量/推理优化问题”。
也许 DSPy 最有潜力的地方,是它的理念非常贴合新的产品研发范式:基准和评测先行,工程化模块保证可控,高质量学习数据是关键。